点操作加法器
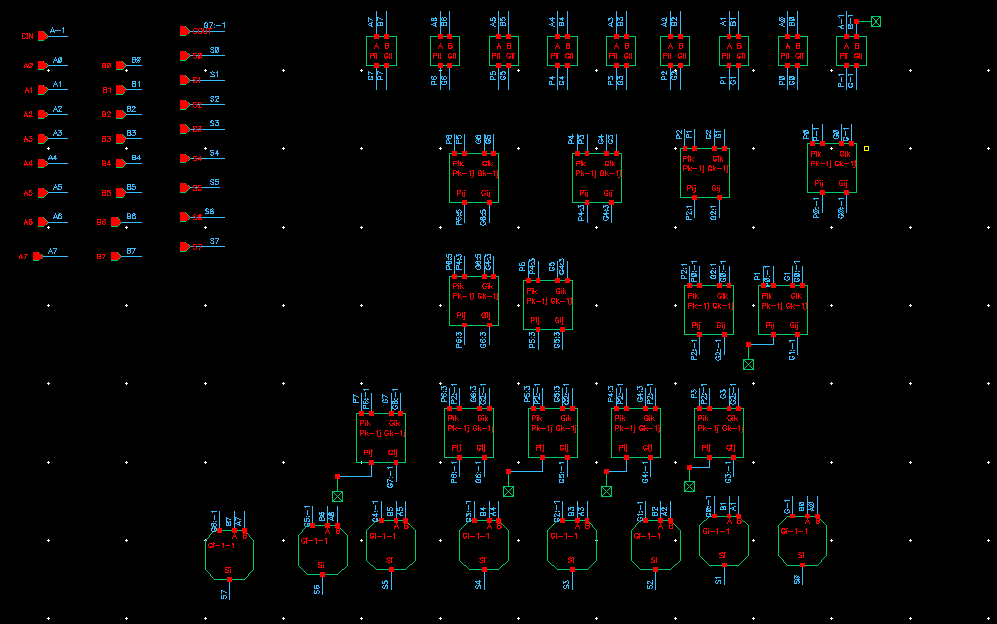
点操作串联和级联1
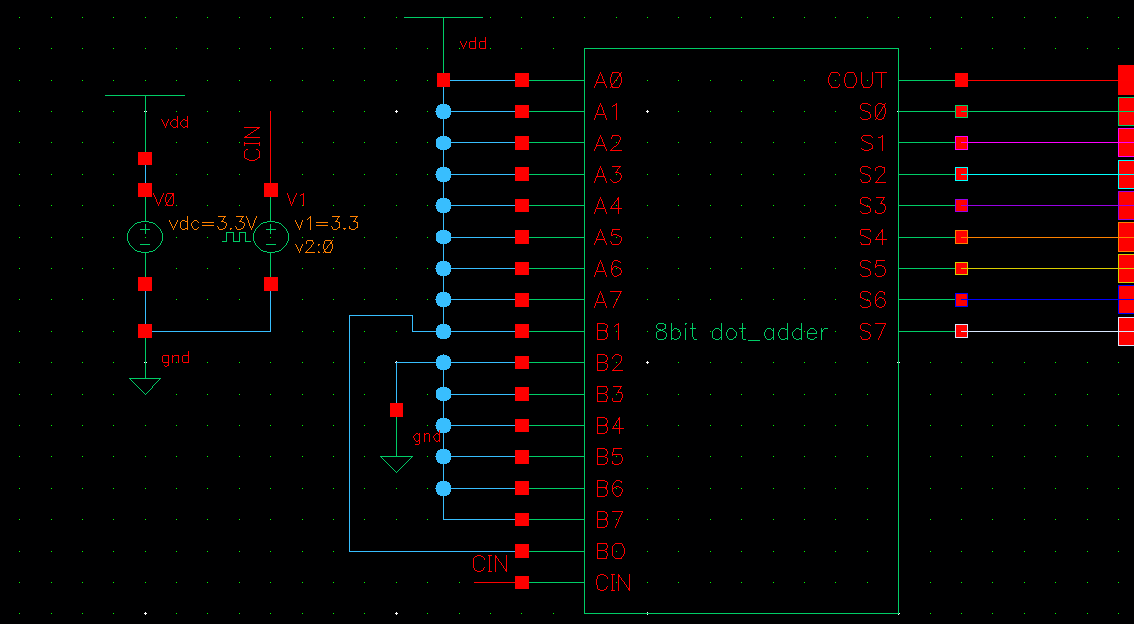
八位加法器点操作电路设计与仿真2
八位的话9个输入输出端口
最后一个直接G7:-1就是进位
 =-
=-
p2:-1
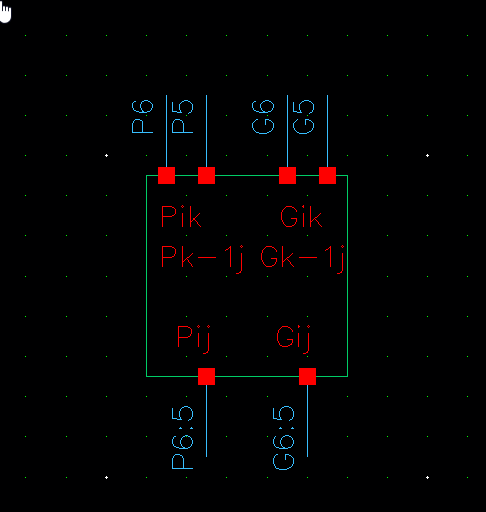
PG6:5接反

11111111,00000011
预测s0一条曲线变化
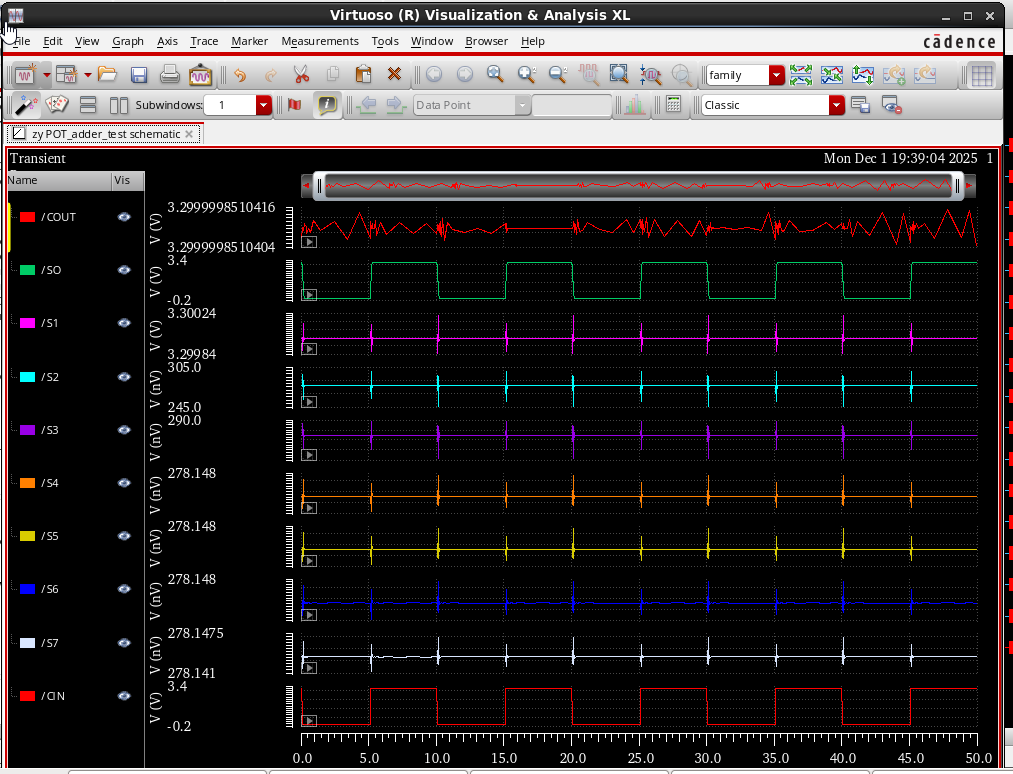
设置数值为 31 (0001 1111)
设置数值为 0 (0000 0000)
输入 CIN:保持 vpulse (0 1)
这个测试的核心逻辑是:
-
当 CIN = 0 时:。
- 二进制结果:
0001 1111
- 二进制结果:
-
当 CIN = 1 时:。
- 二进制结果:
0010 0000
- 二进制结果:
当你点击运行后,你应该看到 6 条曲线发生跳变,其他的保持静止。
-
S0 (Bit 0) : (翻转↓)
- 解释:,留0进1。
-
S1 (Bit 1) : (翻转↓)
- 解释:接收到进位,继续进位。
-
S2 (Bit 2) : (翻转↓)
-
S3 (Bit 3) : (翻转↓)
-
S4 (Bit 4) : (翻转↓)
-
S5 (Bit 5) : (翻转↑ 关键变化)
- 解释:原本 A5=0, B5=0,结果是0。但下面的进位像多米诺骨牌一样一路传到了这里,。进位在这里被“消化”了,没有继续往上传。
-
S6 (Bit 6) : (死线,不变)
- 解释:进位没传上来。
-
S7 (Bit 7) : (死线,不变)
-
COUT: (死线,不变)
正确

-
点操作串联和级联
对于 8位 的情况,它们之间的延时差距并不大(甚至在某些布局布线糟糕的情况下,并行版可能还不如级联版快)。
但如果你把这个逻辑应用到你最终目标的 64位 上,差距就是天壤之别。
下面我用逻辑级数(Logic Depth) ——即信号需要穿过多少层门电路——来量化对比。假设一个“点操作节点”的延时为 1个单位(1T) 。
1. 8位时的对比(差距微小)
-
方案 A:1个 8-bit 全并行 (Full Parallel Tree)
- 核心原理:树形结构, 层。
- 路径:预处理 3级点操作 求和。
- 核心延时:3T
-
方案 B:4个 2-bit 级联 (Cascaded 2-bit)
- 核心原理:串行结构,信号要依次穿过 4 个块。
- 路径:预处理 4级点操作 求和。
- 核心延时:4T
结论: 在 8 位时,3T vs 4T,性能提升只有 25% 左右。你可能感觉不到明显的优势,甚至觉得画全并行树太累了,不划算。
2. 64位时的对比(差距巨大)
这才是你需要做并行点操作的真正原因。假设我们要扩展到 64 位:
-
方案 A:1个 64-bit 全并行 (Full Parallel Tree)
- 核心原理:依然是树形结构, 层。
- 计算公式:层数只增加了 3 层。
- 核心延时:6T
-
方案 B:32个 2-bit 级联 (Cascaded 2-bit)
- 核心原理:信号要依次穿过 32 个块。
- 计算公式: 级。
- 核心延时:32T
结论: 在 64 位时,6T vs 32T,并行方案比级联方案快 5 倍以上!
3. 为什么会这样?
-
级联(Ripple/Cascaded): 延时是 线性增长 (Linear, ) 的。
- 位数翻倍,时间就翻倍。
- 就像排队传话,人越多传得越慢。
-
点操作树(Parallel Prefix): 延时是 对数增长 (Logarithmic, ) 的。
- 位数翻倍,时间只增加固定的一点点(1个单位)。
- 就像公司发广播,10个人和1000个人听到消息的时间几乎是一样的。
-
-
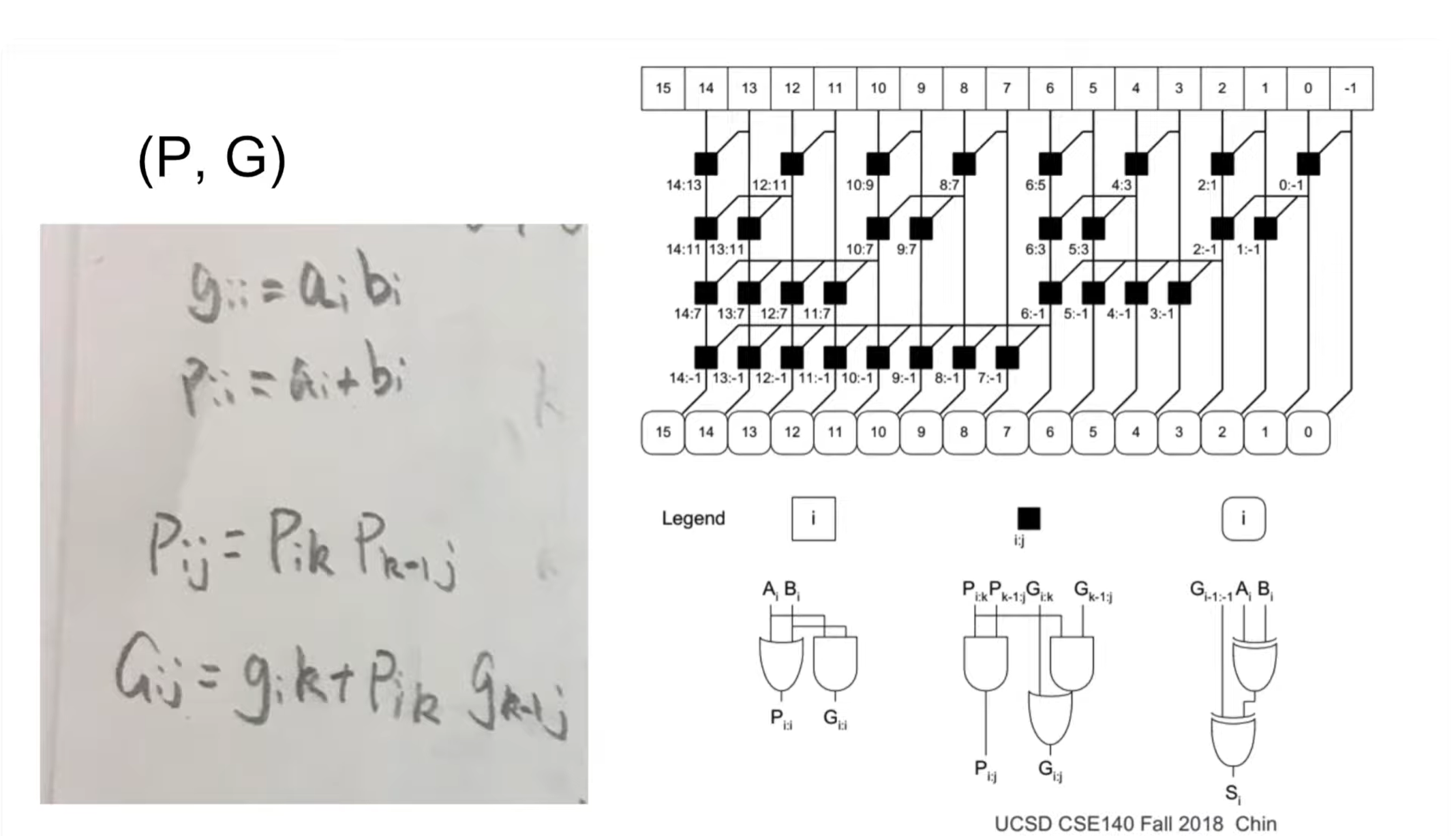
八位加法器点操作电路设计与仿真
1. 电路图
- 静态点操作
点操作运算 在并行加法器中,为了加速进位链的传递,我们不直接等待前一位的进位,而是预先计算两个信号:
-
(Generate - 生成信号) :
- 公式:
- 含义: 如果第 位的两个输入 和 都是 1,那么无论低位是否有进位,第 位一定会向高位生成一个进位。
-
(Propagate - 传播信号) :
- 公式: (或者 )
- 含义: 如果第 位中至少有一个是 1,那么低位传来的进位可以穿过这一位,传播到更高位。
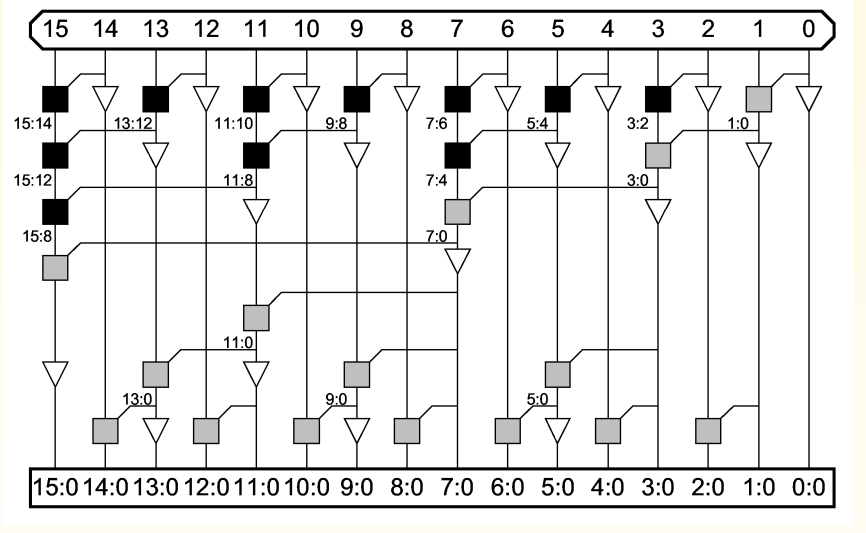
2.进位产生和传播电路
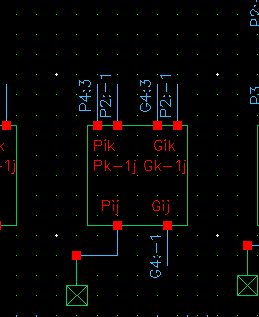
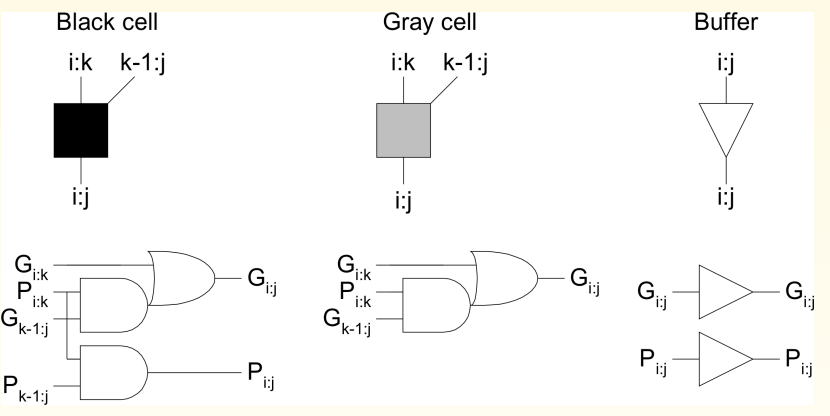
核心操作:Dot Operator
这是并行前缀加法器的数学核心。它通过结合律将小范围的 P/G 信号合并成大范围的 P/G 信号。
A. 组传播信号 ()
- 公式:
- 原理: 要想让进位从位置 一路传播穿过到位置 (跨度 ),进位必须能穿过“低半部分()” 并且 穿过“高半部分()”。所以是逻辑与关系。
B. 组生成信号 ()
-
公式:
-
原理: 在范围 内,产生进位有两种情况:
- 高半部分自己生成了进位: 即 为 1(不需要管低位)。
- 低半部分生成了进位,并且被高半部分传播了出去: 即 为 1(低位生成),且 为 1(高位允许通过)。
- 这两种情况是或(OR)的关系。
- 静态点操作加法器电路
并行前缀加法器(Parallel
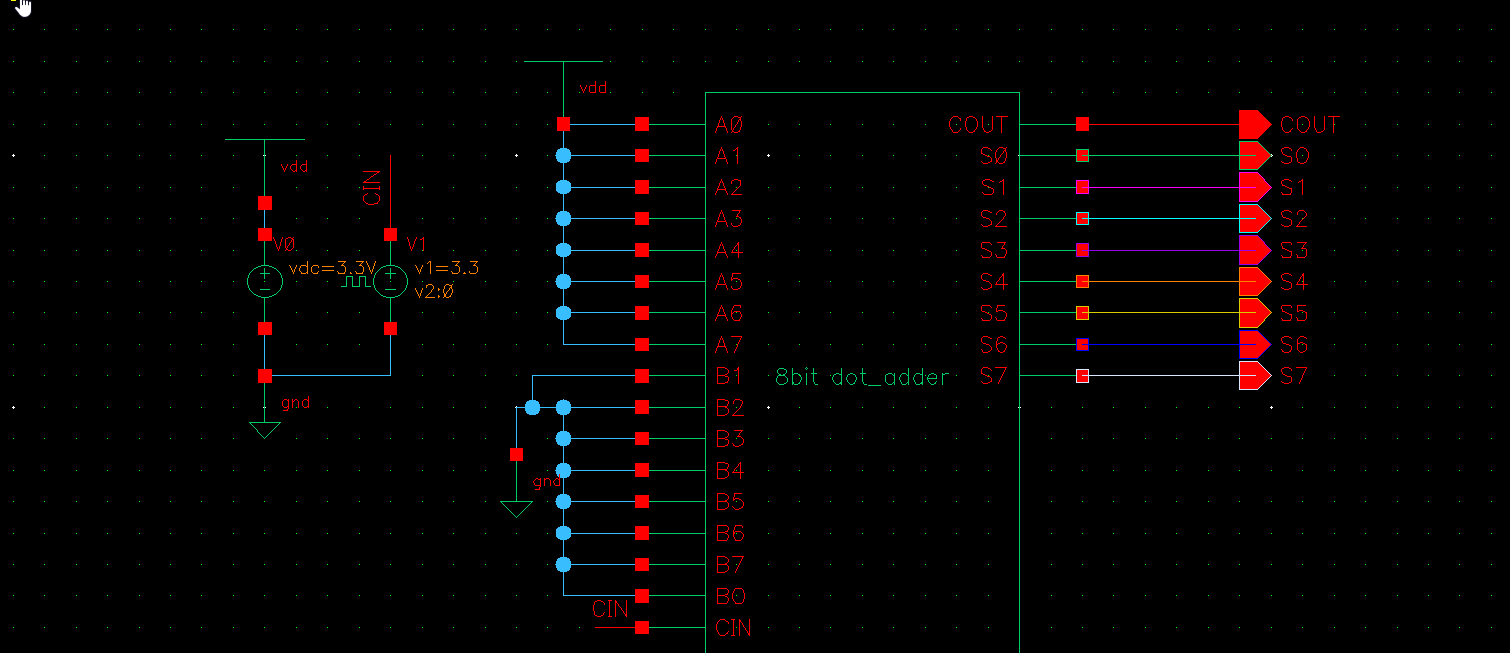
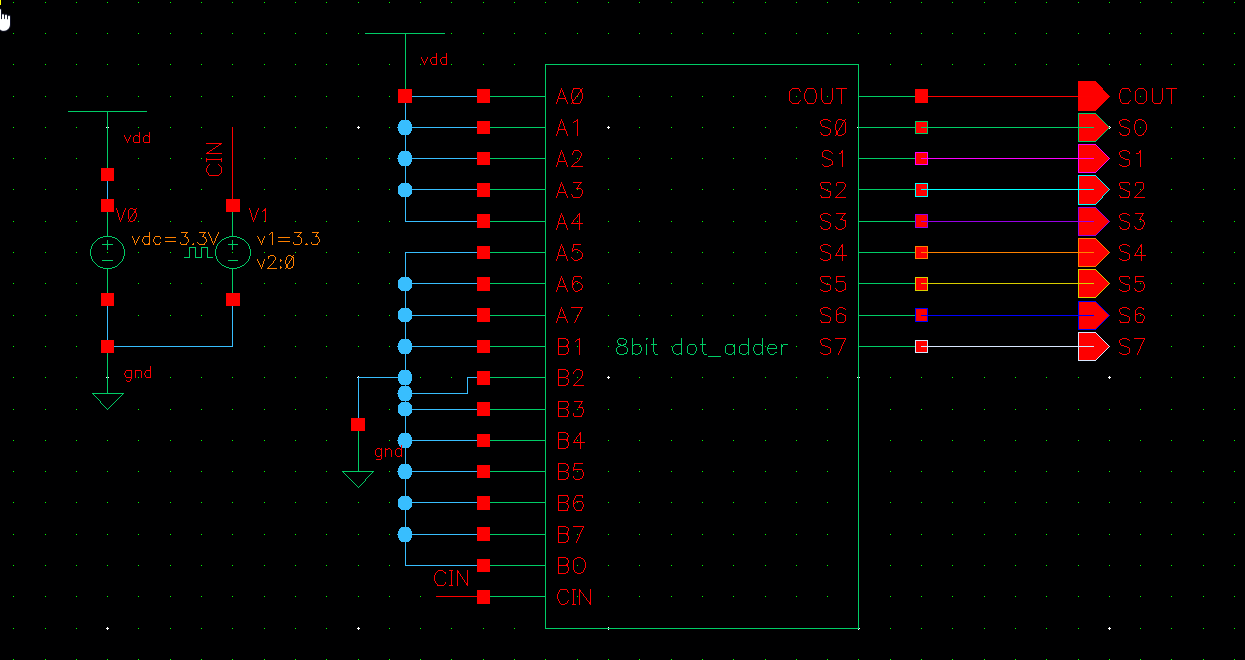
8bit - 测试电路
8bit
8bit 设置数值为 255 (
1111 1111)设置数值为 0 (
0000 0000)输入 CIN:保持
vpulse (0 1)点击运行后,应该看到 9 条曲线发生跳变,其他的保持静止。
预测 S0-S7,COUT 全部翻转
8bit
8bit
设置数值为 31 (
0001 1111)设置数值为 0 (
0000 0000)输入 CIN:保持
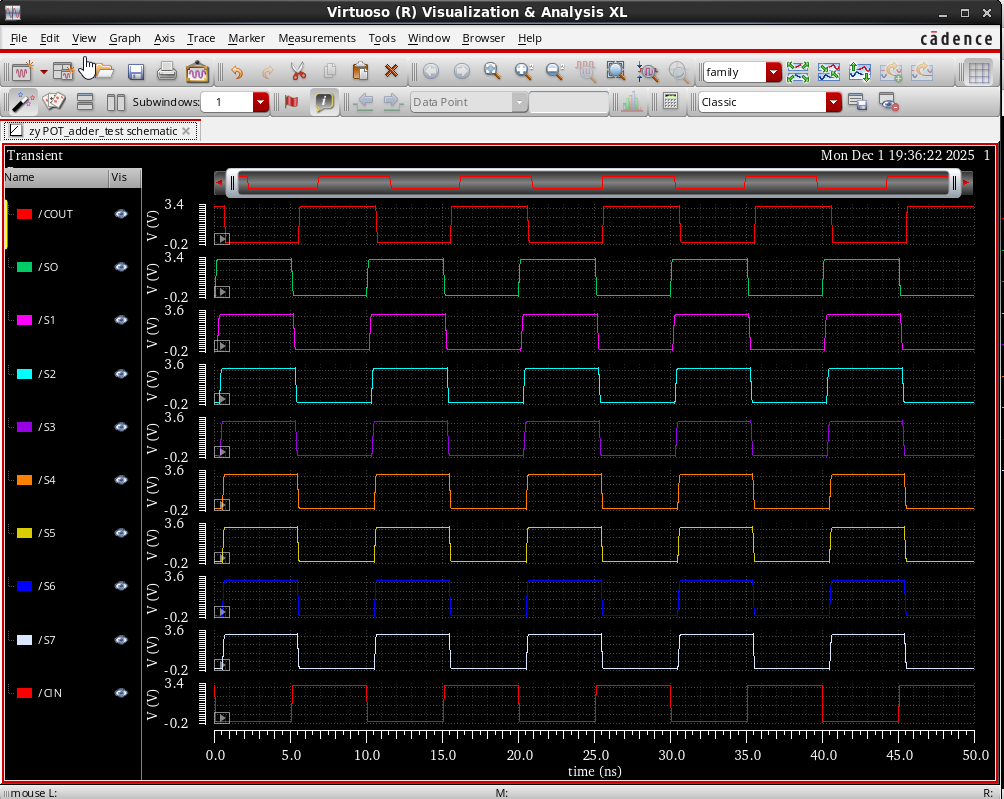
vpulse (0 1)点击运行后,应该看到 6 条曲线发生跳变,其他的保持静止。
3. 仿真结论
1. 设计原理与架构验证
本次设计成功实现了一个基于静态点操作(Static Dot Operator)的 8 位并行前缀加法器。
- 核心逻辑:电路采用了预计算技术,利用 和 提前获取每一位的生成与传播状态。
- 点操作(Dot Operator)应用:通过引入“黑点”操作符(),利用公式 和 ,成功将传统的串行进位链转化为并行的树状结构。这种结构利用逻辑运算的结合律,有效缩短了关键路径的逻辑深度。
2. 仿真功能验证
通过 Cadence Virtuoso 平台对电路进行了瞬态仿真,针对两种极端的进位传播场景进行了验证,结果与理论预测完全一致:
-
**最长路径/全进位测试 (** ) :
- 测试场景:输入 , 。此时所有位的传播信号 均为 1,进位通道全开。
- 结果分析:当 由 0 跳变为 1 时,运算结果由 255 () 变为 256 ()。
- 波形表现:仿真波形显示 S0-S7 全部由高电平翻转为低电平,同时 COUT 由低电平翻转为高电平。共 9 条曲线 发生跳变。
- 结论:该测试证明了加法器的进位链能够从最低位(LSB)完整、正确地传播至最高位(MSB)及进位输出端,验证了最坏情况下的逻辑正确性。
-
**部分进位测试 (** ) :
- 测试场景:输入 , 。低 5 位为 1,高 3 位为 0。
- 结果分析:当 由 0 跳变为 1 时,运算结果由 31 () 变为 32 ()。
- 波形表现:仿真显示 S0-S4 (低 5 位) 由高变低,S5 由低变高,而 S6、S7 和 COUT 保持静止。共 6 条曲线 发生跳变。
- 结论:该测试验证了点操作网络在处理局部进位时的准确性,证明电路能正确地在中间位终止进位传播。